Which do you think can detect image difference best: you or a computer?
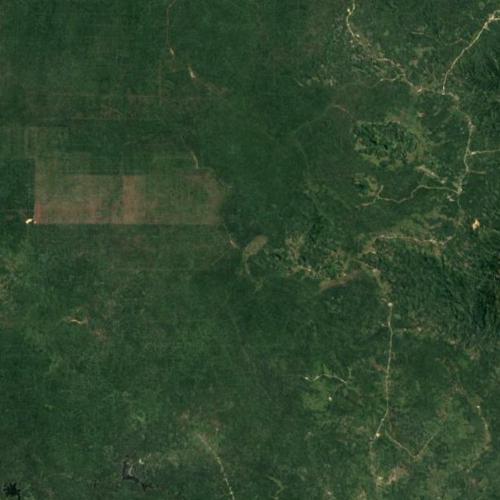
Say you were an environmentalist trying to detect deforestation using historical satellite imagery. Imagine what could happen if computers could detect and predict when, where, and how fast deforestation was happening. This is possible through Machine Learning. Machine Learning is how computers can learn rules and patterns from data to make predictions about new data.
Can a computer use machine learning to be able to tell if deforestation is happening in different areas in Indonesia? Let’s use a tutorial to learn how to use Machine Learning to answer this question.
How does Machine Learning work?
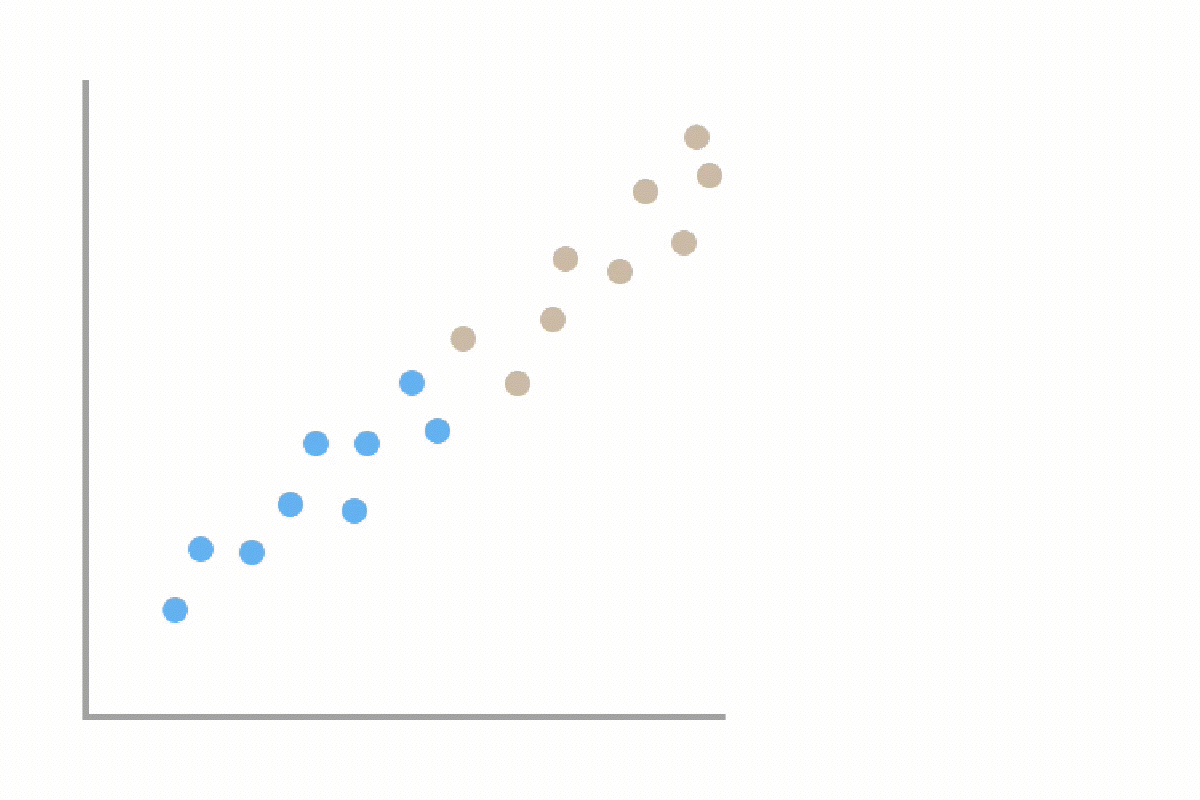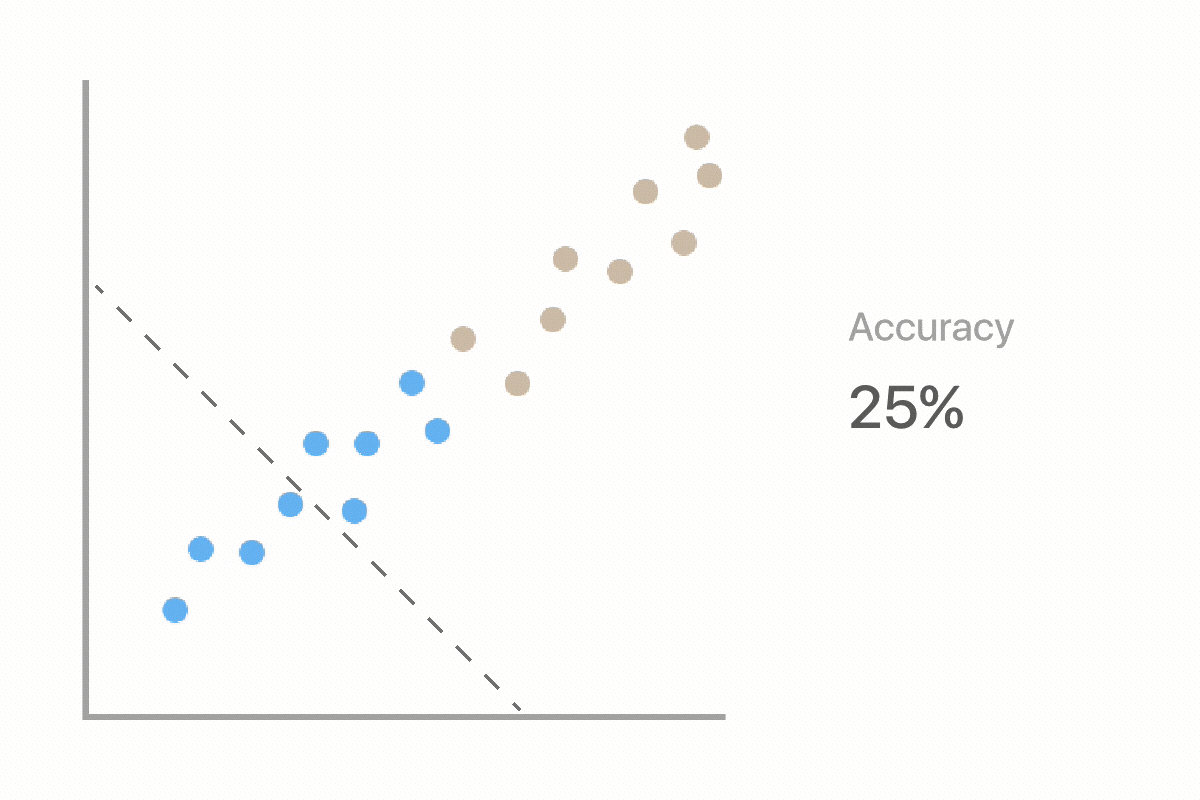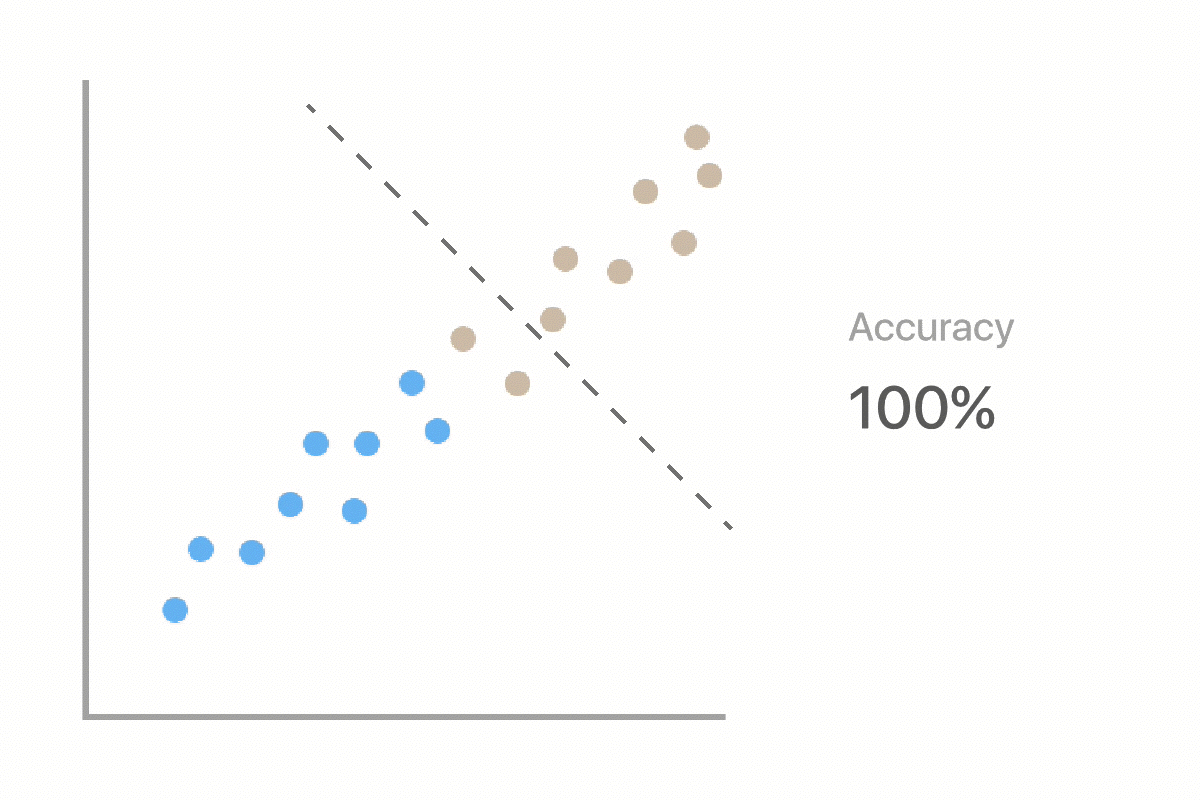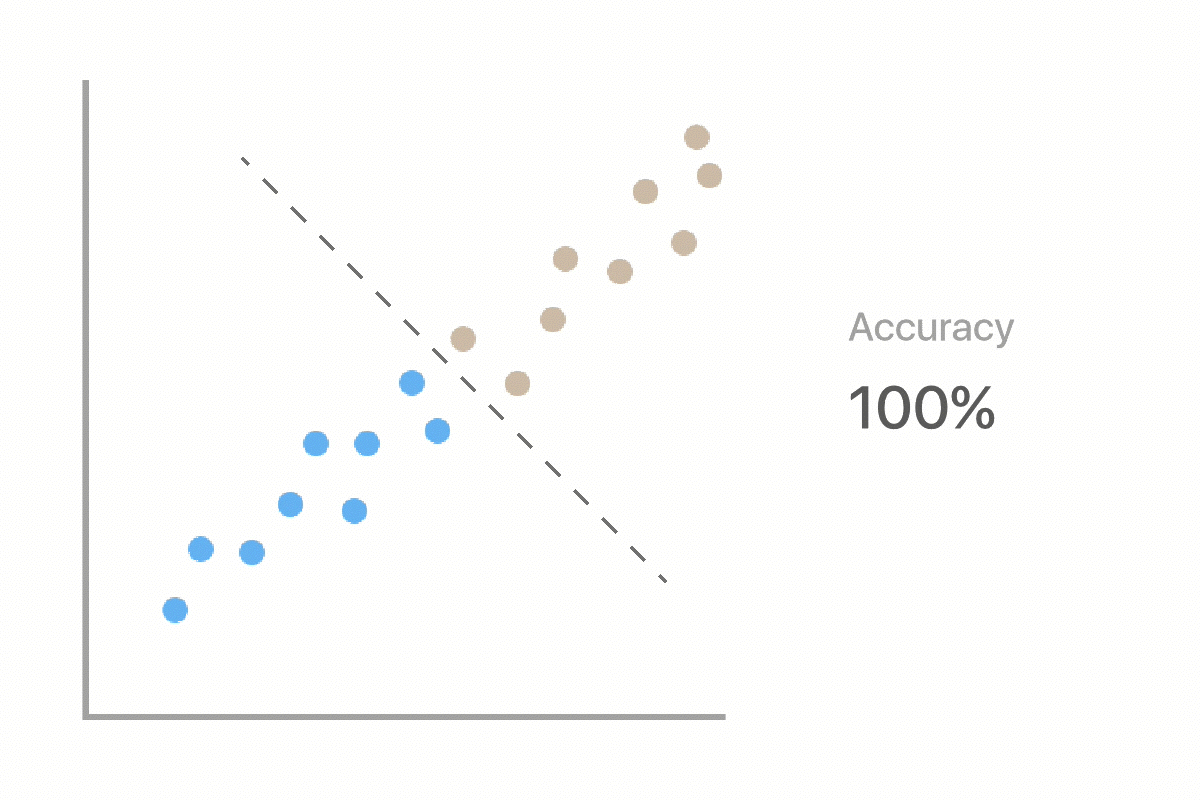
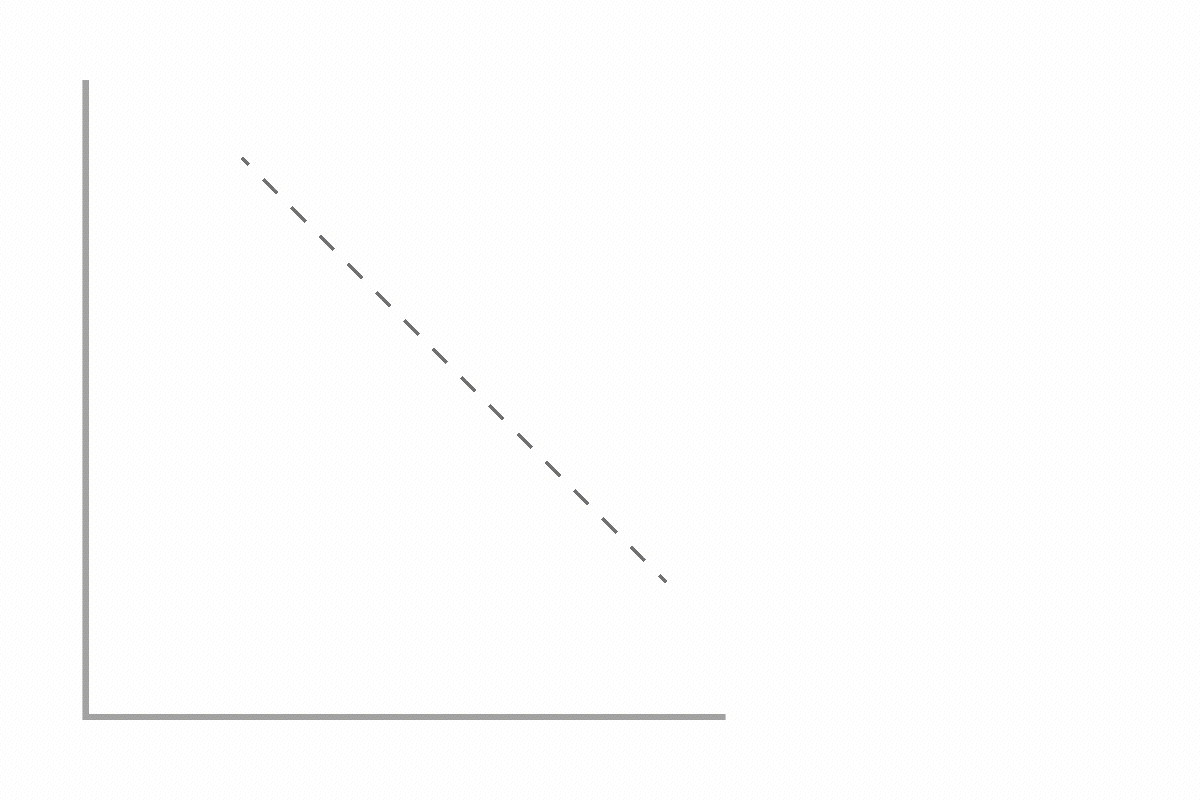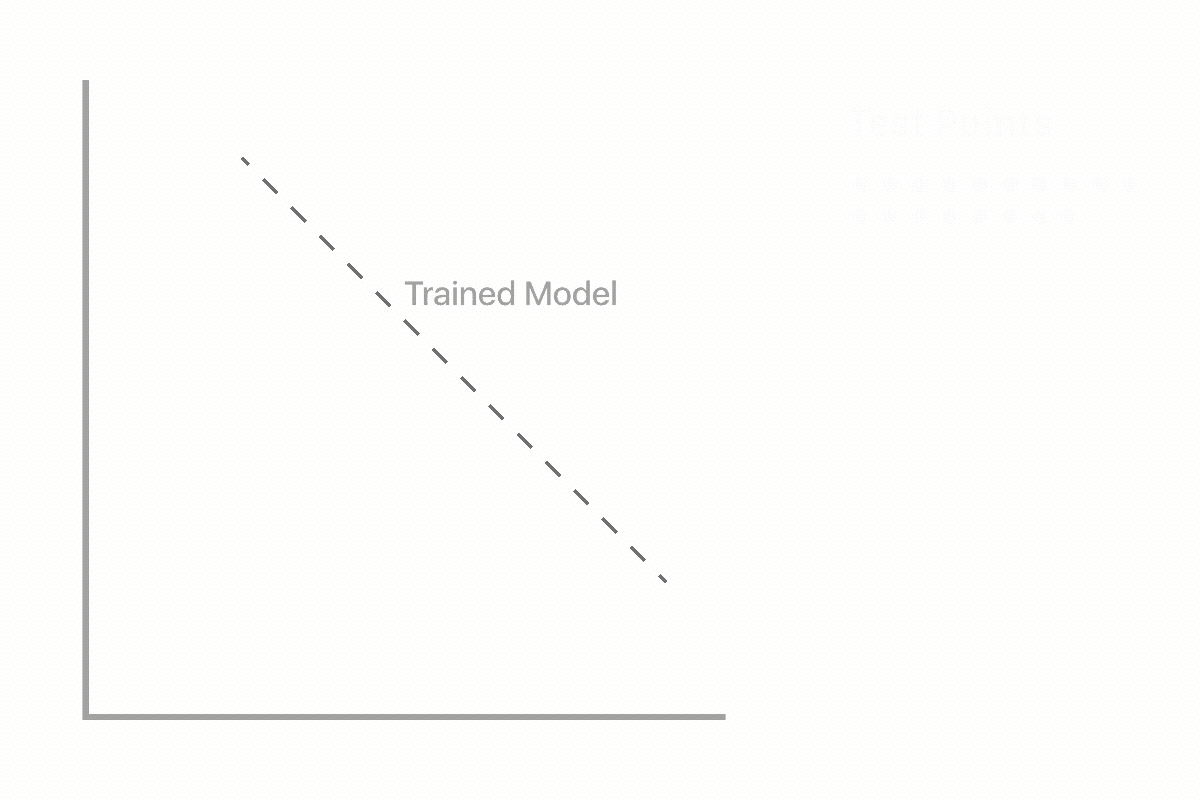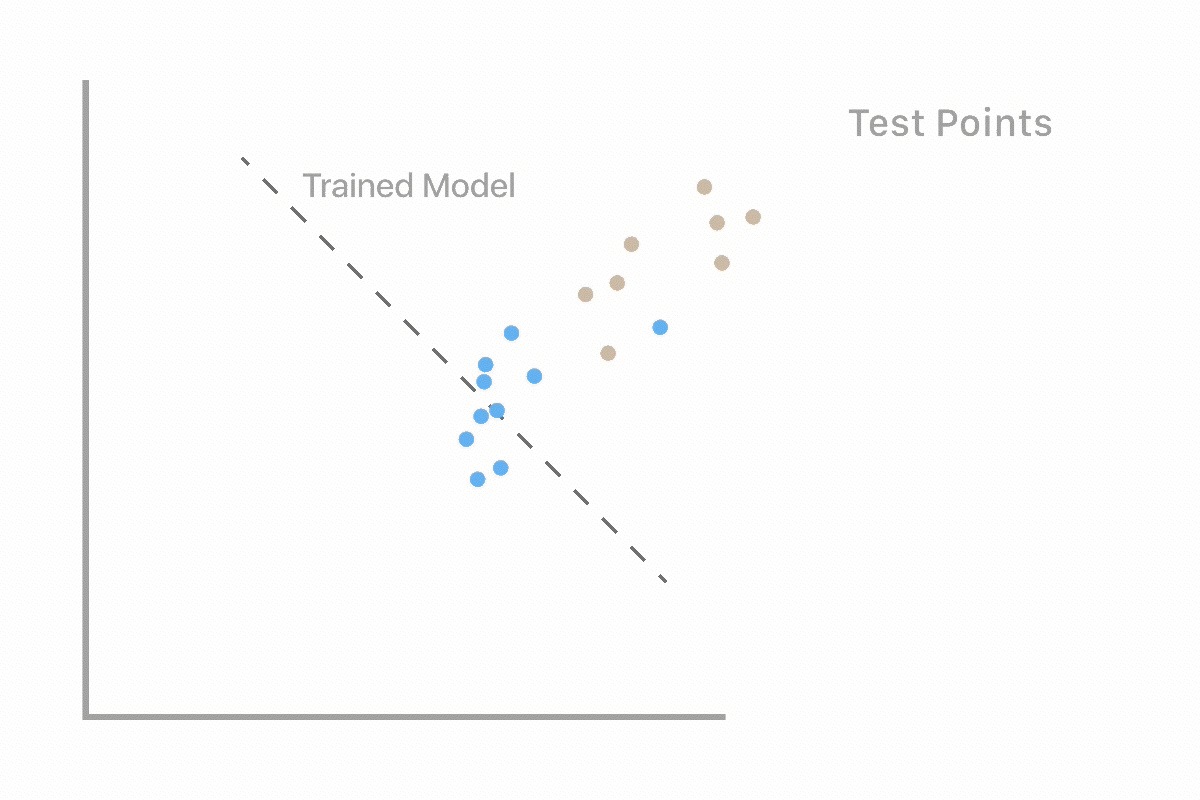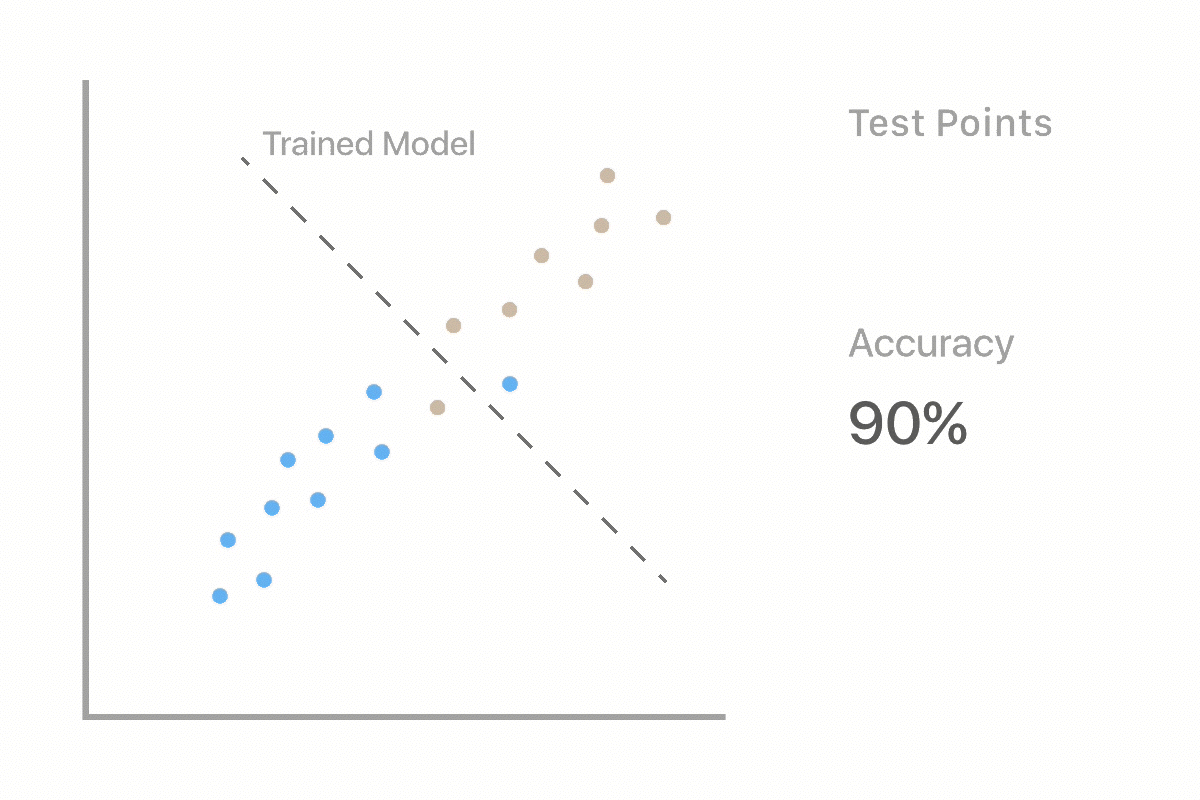
Machine learning uses labeled examples to learn the best rules for separating data into classes (in this case deforestation and non-deforestation). Two major stages in Machine Learning are training and testing. In the training stage, we will train our computer using a subset of our picture dataset that we have already labeled. This will produce a model, which will make predictions on new examples. In the testing stage, we will see how well the model performs when it has to make predictions on unseen data.
As we work through our deforestation example, we will evaluate whether or not the computer can classify our images as well as we can. This is important because we want to ensure that the computer is making accurate predictions compared to ones made by a human.